오랜만에 n8n을 다시 돌려볼려고 했더니, 완전 다 잊어버렸다.
그래서 다시 정리하고 기록해둠
1.[n8n] credentials 설정
- 외부와 연동하는 설정이 되어야 정보를 가져올수 있음

2.구글 API 연동
구글 클라우드 > 프로젝트 생성 > API 연동 설정 > 기타 설정
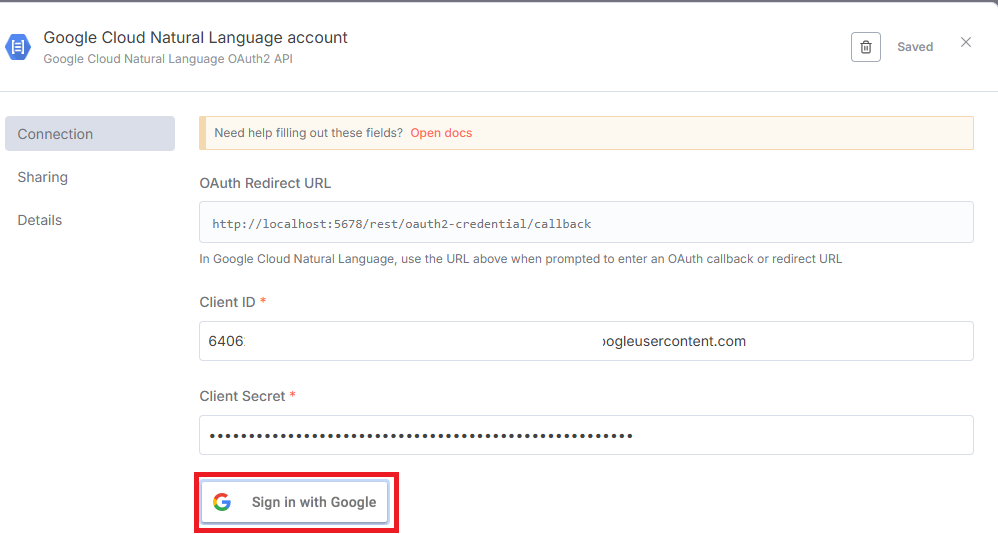
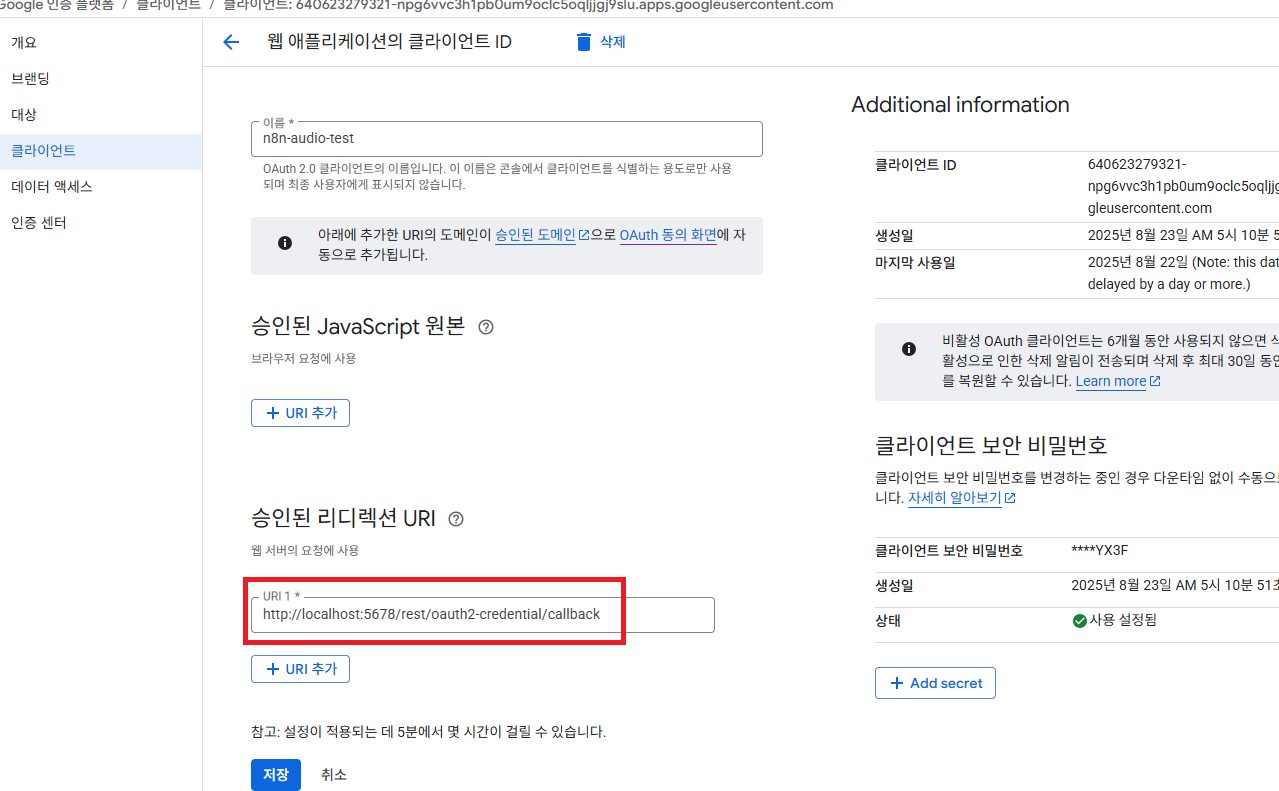
2.1 클라이언트 ID 생성

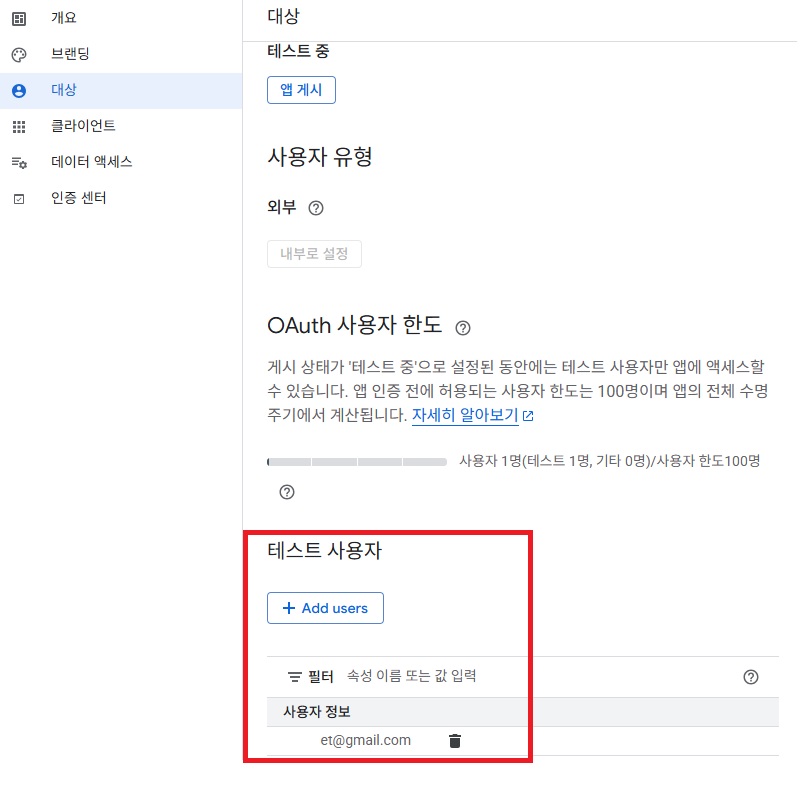
2.2. 데이터 접근 허용

2.3 게시: 인증을 더하라고 나오는데, n8n에서 설정후 무시하고 진행하면 접근이 허용되더라...
: 테스트 모드에서는 7일단위로 인증을 다시 해야한다는게 있어서, 게시를 클릭해서 프로덕션모드로 설정해두면 된다.(앱 인증은 무시가능)

2.4 API 사용 설정
: 인증은 성공했는데, 막상 실행해보면(노드), 아래 오류발생(링크를 따라갔더니 사용허용까지 설정해야 정상적으로 처리됨(26.04.01 확인, 구글 API 인증/사용 방식/설정이 약간 변경이 있었는듯)
Google Sheets API has not been used in project 675402156405 before or it is disabled.
Enable it by visiting https://console.developers.google.com/apis/api/sheets.googleapis.com/overview?project=.... then retry.
If you enabled this API recently, wait a few minutes for the action to propagate to our systems and retry.
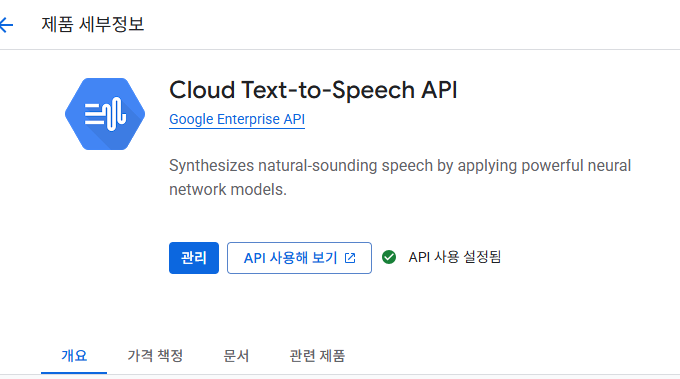
text to speech를 쓴다면 아래도 추가

* 중요: text-to-spee API는 유료인데, 무료300$ 크레딧이 있으면 사용가능(계정을 3개월단위로 새로 생성해서 사용하면된다)
- text to speech API 연결은 아래 인증방식으로 세팅하면된다.

* 이미지 관련해서 사용하던 무료모델이 유료화로 전환됨. 일단 무료 크레딧300$에서 차감된다고 이해했는데, 유료설정후에 사용가능
- gemini API 사용설정 추가

참고: https://ai.google.dev/gemini-api/docs/imagen?hl=ko+curl+-X+POST+%5C#rest
설정은 https://aistudio.google.com/app/api-keys?project=... 에서 진행
> 카드결재가 연계된 계정인데 한번에 10만원이 결재된다고한다. 300크레딧안에서 사용할수 있또록 조심

'AI > n8n' 카테고리의 다른 글
| n8n으로 유튜브 쇼츠 무료 제작하기 | 자동화로 단 30분 만에 영상 만들기 (0) | 2025.09.17 |
|---|---|
| [n8n] AudioBook 완성(Youtobe: Moonlight-Stories) (0) | 2025.09.05 |
| n8n 개발, 소소한 팁 정리 (0) | 2025.09.02 |
| [n8n-step5] youtobe에 업로드하기 (3) | 2025.08.30 |
| [n8n-step4] audio-text 합성(Docker + FFMpeg) (1) | 2025.08.29 |